Software/Datasets
Feature Tracking Analysis for Event Cameras
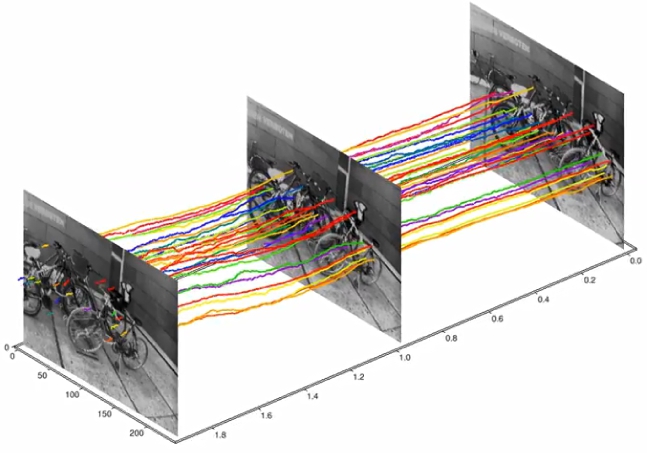
Event cameras are revolutionary sensors that work radically differently from standard cameras. Instead of capturing intensity images at a fixed rate, event cameras measure changes of intensity asynchronously, in the form of a stream of events, which encode per-pixel brightness changes. In the last few years, their outstanding properties (asynchronous sensing, no motion blur, high dynamic range) have led to exciting vision applications, with very low-latency and high robustness.
We release a framework to evaluate event-based feature tracking and provide functionality to evaluate these tracks in real and simulated environments. This package was used for the tracking evaluation in our ECCV'18 paper (PDF, 5 MB), which combines frame- and event-based cameras to do asynchronous and low-latency feature tracking. The package leverages the information provided by frame-based cameras or depth sensors to provide accurate ground truth tracks in a variety of scenes. The code is implemented in Python and can be used to easily generate paper-ready plots and videos.
|
|
Asynchronous, Photometric Feature Tracking using Events and Frames European Conference on Computer Vision |
EMVS: Event-based Multi-View Stereo
Event cameras are revolutionary sensors that work radically differently from standard cameras. Instead of capturing intensity images at a fixed rate, event cameras measure changes of intensity asynchronously, in the form of a stream of events, which encode per-pixel brightness changes. In the last few years, their outstanding properties (asynchronous sensing, no motion blur, high dynamic range) have led to exciting vision applications, with very low-latency and high robustness.
We release the code of our 3-D Event-based Multi-View Stereo (EMVS), that is, for 3D reconstruction with a moving event camera. Our method elegantly exploits two inherent properties of event cameras: (1) their ability to respond to scene edges (which naturally provide semi-dense geometric information) and (2) the fact that they provide continuous measurements as they move. The code provided is implemented in C++ and produces accurate, semi-dense depth maps without requiring any explicit data association or intensity estimation. The code is computationally efficient and runs in real-time on a CPU.
|
|
EMVS: Event-Based Multi-View Stereo - 3D Reconstruction with an Event Camera in Real-Time International Journal of Computer Vision, 2017. |
ESIM: an Open Event Camera Simulator

Event cameras are revolutionary sensors that work radically differently from standard cameras. Instead of capturing intensity images at a fixed rate, event cameras measure changes of intensity asynchronously, in the form of a stream of events, which encode per-pixel brightness changes. In the last few years, their outstanding properties (asynchronous sensing, no motion blur, high dynamic range) have led to exciting vision applications, with very low-latency and high robustness.
We present ESIM: an efficient event camera simulator implemented in C++ and available open source. ESIM can simulate arbitrary camera motion in 3D scenes, while providing events, standard images, inertial measurements, with full ground truth information including camera pose, velocity, as well as depth and optical flow maps.
|
|
ESIM: an Open Event Camera Simulator Conference on Robot Learning (CoRL), Zurich, 2018. |
Evaluation Toolbox for Visual(-Inertial) Odometry
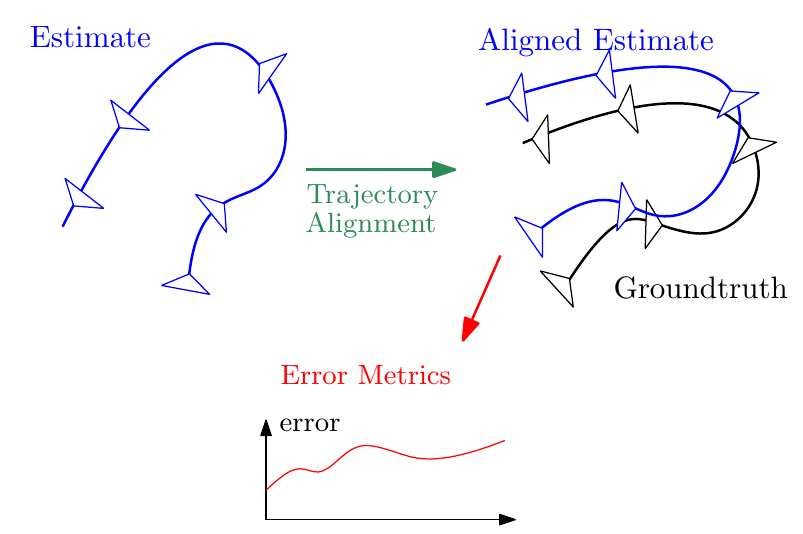
In this tutorial, we provide principled methods to quantitatively evaluate the quality of an estimated trajectory from visual(-inertial) odometry (VO/VIO), which is the foundation of benchmarking the accuracy of different algorithms. First, we show how to determine the transformation type to use in trajectory alignment based on the specific sensing modality (i.e., monocular, stereo and visual-inertial). Second, we describe commonly used error metrics (i.e., the absolute trajectory error and the relative error) and their strengths and weaknesses. To make the methodology presented for VO/VIO applicable to other setups, we also generalize our formulation to any given sensing modality. To facilitate the reproducibility of related research, we publicly release our implementation of the methods described in this tutorial.
More information on the GitHub page.
|
|
A Tutorial on Quantitative Trajectory Evaluation for Visual(-Inertial) Odometry IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, 2018. PDF (PDF, 483 KB) PPT (PPTX, 8041 KB) VO/VIO Evaluation Toolbox |
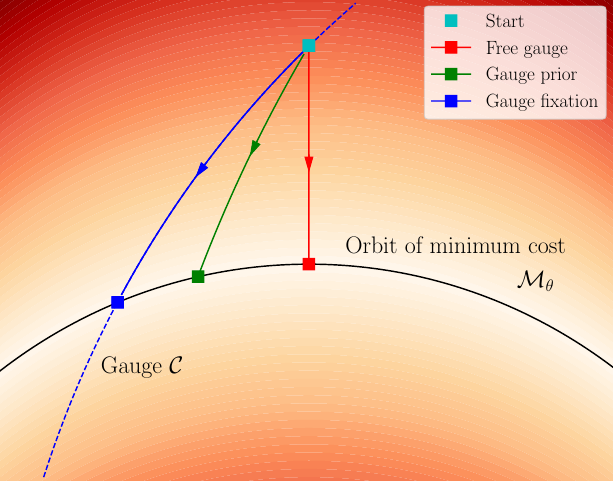
Covariance Transformation for Visual-Inertial Systems
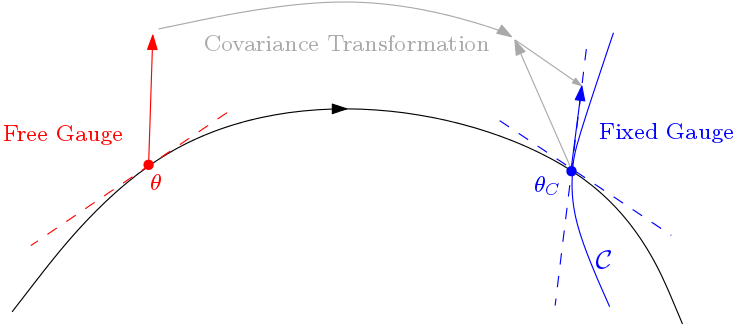
It is well known that visual-inertial state estimation is possible up to a four degrees-of-freedom (DoF) transformation (rotation around gravity and translation), and the extra DoFs ("gauge freedom") have to be handled properly. While different approaches for handling the gauge freedom have been used in practice, no previous study has been carried out to systematically analyze their differences. In this paper, we present the first comparative analysis of different methods for handling the gauge freedom in optimization-based visual-inertial state estimation. We experimentally compare three commonly used approaches: fixing the unobservable states to some given values, setting a prior on such states, or letting the states evolve freely during optimization. Specifically, we show that (i) the accuracy and computational time of the three methods are similar, with the free gauge approach being slightly faster; (ii) the covariance estimation from the free gauge approach appears dramatically different, but is actually tightly related to the other approaches. Our findings are validated both in simulation and on real-world datasets and can be useful for designing optimization-based visual-inertial state estimation algorithms.
More information on the GitHub page.
|
|
On the Comparison of Gauge Freedom Handling in Optimization-based Visual-Inertial State Estimation IEEE Robotics and Automation Letters (RA-L), 2018. |
NetVLAD in Python/TensorFlow
NetVLAD (website, paper) is a place recognition neural network which takes an image as input and produces a vector as output. If two images are taken in the same place, the Euclidean between these vectors is small, otherwise not. Using nearest-neighbours search on these vectors, the authors have shown excellent place recognition performance, even under severe appearance changes.
Unfortunately, the full network has officially so far only been implemented in Matlab, rendering deployment on non-desktop PCs and robots tedious.
We are happy to announce a Python/Tensorflow port of the FULL network, approved by the original authors and available here. The repository contains code which allows plug-and-play python deployment of the best off-the-shelf model made available by the authors. We have thoroughly tested that the ported model produces a similar output to the original Matlab implementation, as well as excellent place recognition performance on KITTI 00. The repository does not contain code to train the network, however, it should be easy to adapt to other models trained in Matlab. In our own research, we have previously used NetVLAD here (PDF, 3 MB) and here (PDF, 629 KB), and will continue to use it extensively.
More information on the GitHub page.
References
|
|
NetVLAD: CNN architecture for weakly supervised place recognition IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. |

Data-Efficient Decentralized Visual SLAM
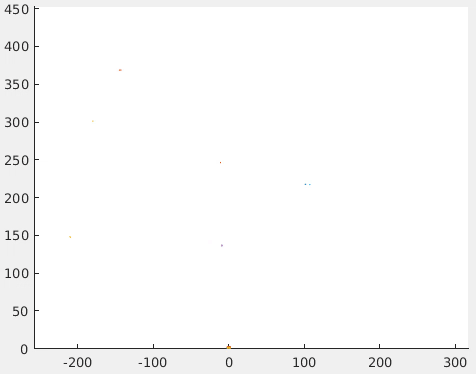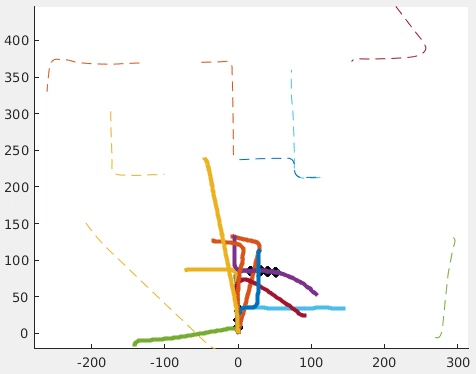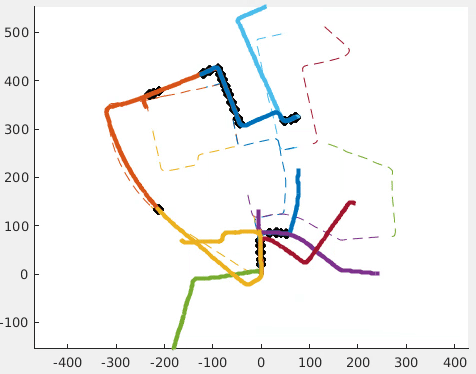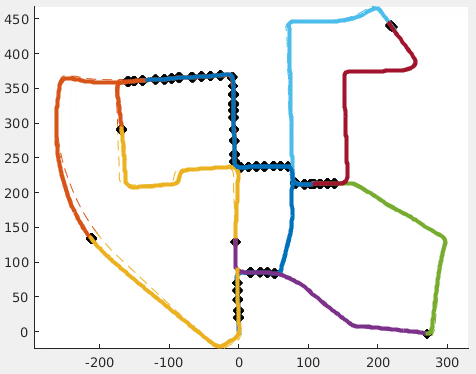
Decentralized visual simultaneous localization and mapping (SLAM) is a powerful tool for multi-robot applications in environments where absolute positioning is not available. Being visual, it relies on cheap, lightweight and versatile cameras, and, being decentralized, it does not rely on communication to a central entity. In this work, we integrate state-of-theart decentralized SLAM components into a new, complete decentralized visual SLAM system. To allow for data association and optimization, existing decentralized visual SLAM systems exchange the full map data among all robots, incurring large data transfers at a complexity that scales quadratically with the robot count. In contrast, our method performs efficient data association in two stages: first, a compact full-image descriptor is deterministically sent to only one robot. Then, only if the first stage succeeded, the data required for relative pose estimation is sent, again to only one robot. Thus, data association scales linearly with the robot count and uses highly compact place representations. For optimization, a state-of-theart decentralized pose-graph optimization method is used. It exchanges a minimum amount of data which is linear with trajectory overlap. We characterize the resulting system and identify bottlenecks in its components. The system is evaluated on publicly available datasets and we provide open access to the code.
More information on the GitHub page.
References
|
|
Data-Efficient Decentralized Visual SLAM IEEE International Conference on Robotics and Automation (ICRA), 2018. PDF (PDF, 629 KB)ICRA18 VIdeo Pitch PPT (PPTX, 93 MB) Code and Data |
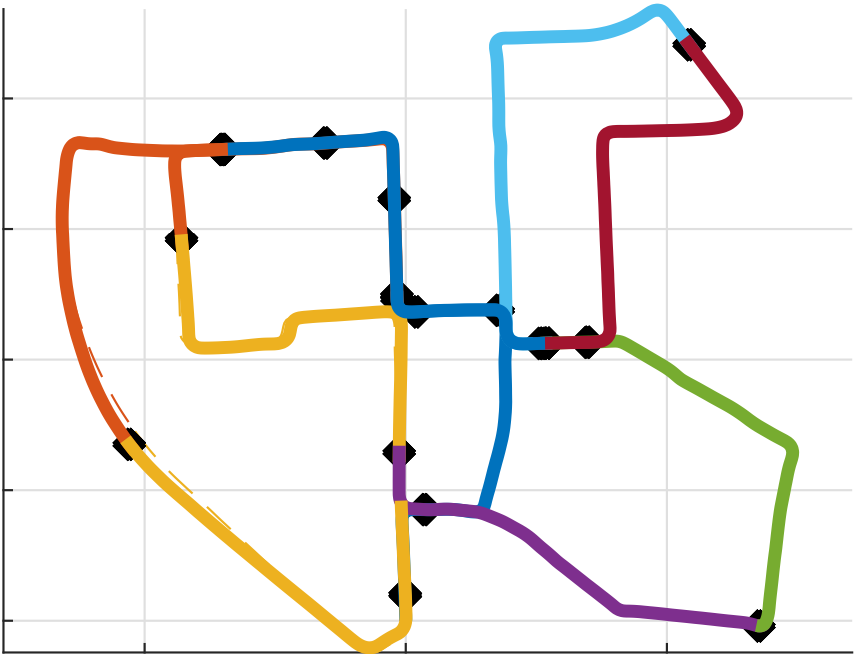
Fast Event-based Corner Detection

Inspired by frame-based pre-processing techniques that reduce an image to a set of features, which are typically the input to higher-level algorithms, we propose a method to reduce an event stream to a corner event stream. Our goal is twofold: extract relevant tracking information (corners do not suffer from the aperture problem) and decrease the event rate for later processing stages. Our event-based corner detector is very efficient due to its design principle, which consists of working on the Surface of Active Events (a map with the timestamp of the latest event at each pixel) using only comparison operations. Our method asynchronously processes event by event with very low latency. Our implementation is capable of processing millions of events per second on a single core (less than a micro-second per event) and reduces the event rate by a factor of 10 to 20.
More information on theGithub page
References
|
|
Fast Event-based Corner Detection British Machine Vision Conference (BMVC), London, 2017. PDF (PDF, 1 MB) Poster (PDF, 1008 KB) YouTube Open-Source Code |

RPG Quadrotor Control Framework

We provide a complete framework for flying quadrotors based on control algorithms developed by the Robotics and Perception Group. We also provide an interface to the RotorS Gazebo plugins to use our algorithms in simulation. Together with the provided simple trajectory generation library, this can be used to test and use our sofware in simulation only. We also provide some utility to command a quadrotor with a gamepad through our framework as well as some calibration routines to compensate for varying battery voltage. Finally, we provide an interface to communicate with flight controllers used for First-Person-View racing.
More information on the project page.
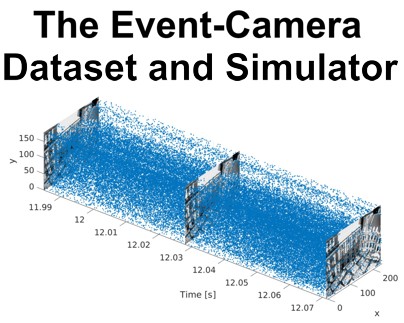
The Event-Camera Dataset and Simulator

This dataset presents the world's first collection of datasets with an event-based camera for high-speed robotics. The data also include intensity images, inertial measurements, and ground truth from a motion-capture system. An event-based camera is a revolutionary vision sensor with three key advantages: a measurement rate that is almost 1 million times faster than standard cameras, a latency of 1 microsecond, and a high dynamic range of 130 decibels (standard cameras only have 60 dB). These properties enable the design of a new class of algorithms for high-speed robotics, where standard cameras suffer from motion blur and high latency. All the data are released both as text files and binary (i.e., rosbag) files.
More information on the dataset website.
References
|
|
The Event-Camera Dataset and Simulator: Event-based Data for Pose Estimation, Visual Odometry, and SLAM International Journal of Robotics Research, Vol. 36, Issue 2, pages 142-149, Feb. 2017. |
Information Gain Based Active Reconstruction Framework

The Information Gain Based Active Reconstruction Framework is a modular, robot-agnostic, software package for performing next-best-view planning for volumetric object reconstruction using a range sensor. Our implementation can be easily adapted to any mobile robot equipped with any camera-based range sensor (e.g stereo camera, structured light sensor) to iteratively observe an object to generate a volumetric map and a point cloud model. The algorithm allows the user to define the information gain metric for choosing the next best view, and many formulations for these metrics are evaluated and compared in our ICRA paper. This framework is released open source as a ROS-compatible package for autonomous 3D reconstruction tasks.
Download the code from GitHub.
Check out a video of the system in action on YouTube.
References
|
|
An Information Gain Formulation for Active Volumetric 3D Reconstruction IEEE International Conference on Robotics and Automation (ICRA), Stockholm, 2016. |

Fisheye and Catadioptric Synthetic Datasets for Visual Odometry

We provide two synthetic scenes (vehicle moving in a city, and flying robot hovering in a confined room). For each scene, three different optics were used (perspective, fisheye and catadioptric), but the same sensor is used (keeping the image resolution constant). These datasets were generated using Blender, using a custom omnidirectional camera model, which we release as an open-source patch for Blender.
Download the datasets from here.
References
|
|
Benefit of Large Field-of-View Cameras for Visual Odometry IEEE International Conference on Robotics and Automation (ICRA), Stockholm, 2016. PDF (PDF, 6 MB) YouTube Research page (datasets and software) |

Event Lifetime
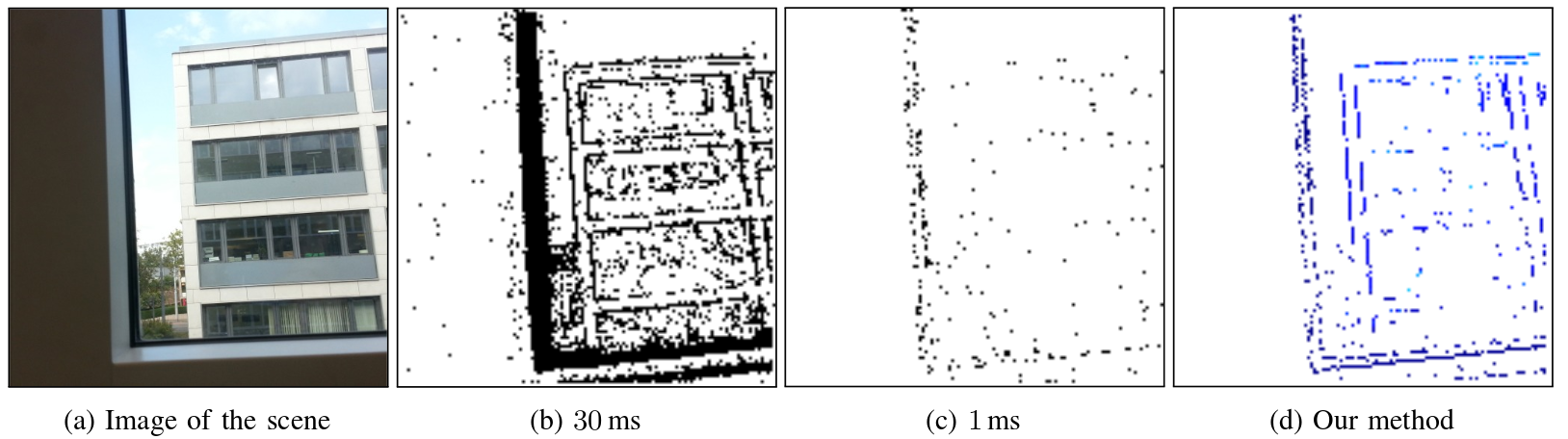
The lifetime of an event is the time that it takes for the moving brightness gradient causing the event to travel a distance of 1 pixel. The provided algorithm augments each event with its lifetime, which is computed from the event's velocity on the image plane. The generated stream of augmented events gives a continuous representation of events in time, hence enabling the design of new algorithms that outperform those based on the accumulation of events over fixed, artificially-chosen time intervals. A direct application of this augmented stream is the construction of sharp gradient (edge-like) images at any time instant.
References
|
|
Lifetime Estimation of Events from Dynamic Vision Sensors IEEE International Conference on Robotics and Automation (ICRA), Seattle, 2015. |
Indoor Dataset of Quadrotor with Down-Looking Camera

This dataset contains the recording of the raw images, IMU measurements as well as the ground truth poses of a quadrotor flying a circular trajectory in a office size environment.
REMODE: Real-time, Probabilistic, Monocular, Dense Reconstruction

REMODE is a novel method to estimate dense and accurate depth maps from a single moving camera. A probabilistic depth measurement is carried out in real time on a per-pixel basis and the computed uncertainty is used to reject erroneous estimations and provide live feedback on the reconstruction progress. REMODE uses a novel approach to depth map computation that combines Bayesian estimation and recent development on convex optimization for image processing. In the reference paper below, we demonstrate that our method outperforms state-of-the-art techniques in terms of accuracy, while exhibiting high efficiency in memory usage and computing power. Our CUDA-based implementation runs at 50Hz on a laptop computer and is released as open-source software (code here).
Download the code from GitHub.
References
|
|
REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, 2014. |

SVO: Semi-direct Visual Odometry

SVO is a Semi-direct, monocular Visual Odometry algorithm that is precise, robust, and faster than current state-of-the-art methods. The semi-direct approach eliminates the need of costly feature extraction and robust matching techniques for motion estimation. SVO operates directly on pixel intensities, which results in subpixel precision at high frame-rates. A probabilistic mapping method that explicitly models outlier and depth uncertainty is used to estimate 3D points, which results in fewer outliers and more reliable points. Precise and high frame-rate motion estimation brings increased robustness in scenes of little, repetitive, and high-frequency texture. The algorithm is applied to micro-aerial-vehicle state-estimation in GPS-denied environments and runs at 55 frames per second on the onboard embedded computer and at more than 400 frames per second on anm i7 consumer laptop and more than 70 frames per second on a smartphone computer (e.g., Odroid or Samsung Galaxy phones).
Download the code from GitHub.
References
|
|
SVO: Fast Semi-Direct Monocular Visual Odometry IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, 2014. |
ROS Driver and Calibration Tool for the Dynamic Vision Sensor (DVS)
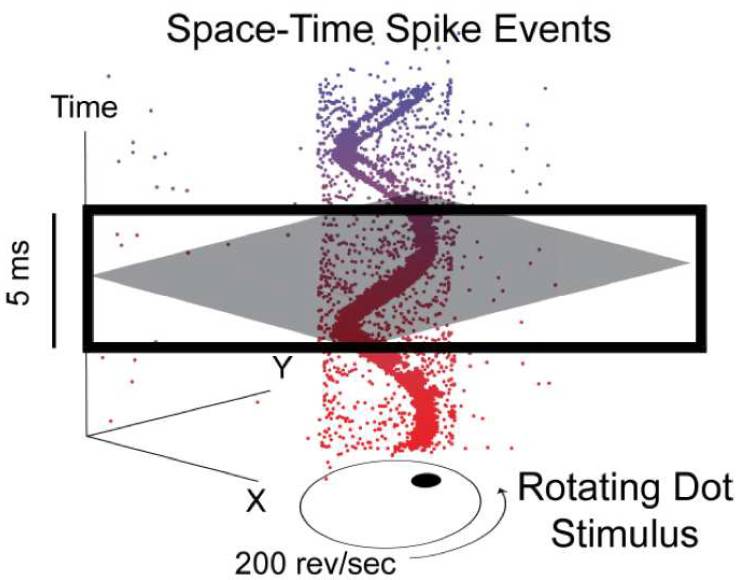
The RPG DVS ROS Package allow to use the Dynamic Vision Sensor (DVS) within the Robot Operating System (ROS). It also contains a calibration tool for intrinsic and stereo calibration using a blinking pattern.
The code with instructions on how to use it is hosted on GitHub.
Authors: Elias Mueggler, Basil Huber, Luca Longinotti, Tobi Delbruck
References
E. Mueggler, B. Huber, D. Scaramuzza Event-based, 6-DOF Pose Tracking for High-Speed Maneuvers, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Chicago, 2014. [ PDF (PDF, 926 KB) ]
A. Censi, J. Strubel, C. Brandli, T. Delbruck, D. Scaramuzza Low-latency localization by Active LED Markers tracking using a Dynamic Vision Sensor, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, 2013. [ PDF (PDF, 1 MB) ]
P. Lichtsteiner, C. Posch, T. Delbruck A 128x128 120dB 15us Latency Asynchronous Temporal Contrast Vision Sensor, IEEE Journal of Solid State Circuits, Feb. 2008, 43(2), 566-576. [ PDF (PDF, 2 MB) ]
A Monocular Pose Estimation System based on Infrared LEDs

Mutual localization is a fundamental component for multi-robot missions. Our monocular pose estimation system consists of multiple infrared LEDs and a camera with an infrared-pass filter. The LEDs are attached to the robot that we want to track, while the observing robot is equipped with the camera.
The code with instructions on how to use it is hosted on GitHub.
Reference
Matthias Faessler, Elias Mueggler, Karl Schwabe and Davide Scaramuzza, A Monocular Pose Estimation System based on Infrared LEDs, Proc. IEEE International Conference on Robotics and Automation (ICRA), 2014, Hong Kong. [ PDF (PDF, 1 MB) ]
Torque Control of a KUKA youBot Arm

Existing control schemes for the KUKA youBot arm, such as directly controlling joint positions or velocities, are not suited for close tracking of end effector trajectories. A torque controller, based on the dynamical model of the youBot arm, was implemented to overcome this limitation. Complementary to the controller, a framework to automatically generate trajectories was developed.
The code with instructions on how to use it is hosted on GitHub. Details are provided in the Master Thesis (PDF, 3 MB) of Benjamin Keiser.
Authors: Benjamin Keiser, Matthias Faessler, Elias Mueggler
Reference
B. Keiser, E. Mueggler, M. Faessler, D. Scaramuzza Torque Control of a KUKA youBot Arm, Master Thesis, University of Zurich, September, 2013. [ PDF (PDF, 3 MB) ]
Dataset: Air-Ground Matching of Airborne images with Google Street View data

Matching airborne images to ground level ones is a challenging problem since in this case extreme changes in viewpoint and scale can be found between the aerial Micro Aerial Vehicle (MAV) images and the ground-level images, aside the challenges present in ground visual search algorithms used in UGV applications, such as illumination, lens distortions, over season variation of the vegetation, and scene changes between the query and the database images.
Our dataset consists of image data captured with a small quadroctopter flying in the streets of Zurich (up to 15 meters from the ground), along a path of 2km, including: (1) aerial MAV Images, (2) ground-level Google Street View Images, (3) ground-truth confusion matrix, and (4) GPS data (geotags) for every database image.
Authors: Andras Majdik and Yves Albers-Schoenberg
References
A.L. Majdik, D. Verda, Y. Albers-Schoenberg, D. Scaramuzza Air-ground Matching: Appearance-based GPS-denied Urban Localization of Micro Aerial Vehicles Journal of Field Robotics, 2015. [ PDF (PDF, 3 MB) ]
A. L. Majdik, D. Verda, Y. Albers-Schoenberg, D. Scaramuzza Micro Air Vehicle Localization and Position Tracking from Textured 3D Cadastral Models IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, 2014. [ PDF (PDF, 8 MB) ]
A. Majdik, Y. Albers-Schoenberg, D. Scaramuzza. MAV Urban Localization from Google Street View Data, IROS'13, IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS'13, 2013. [ PDF (PDF, 1 MB) ] [ PPT (PPT, 346 KB) ]
Perspective 3-Point (P3P) Algorithm
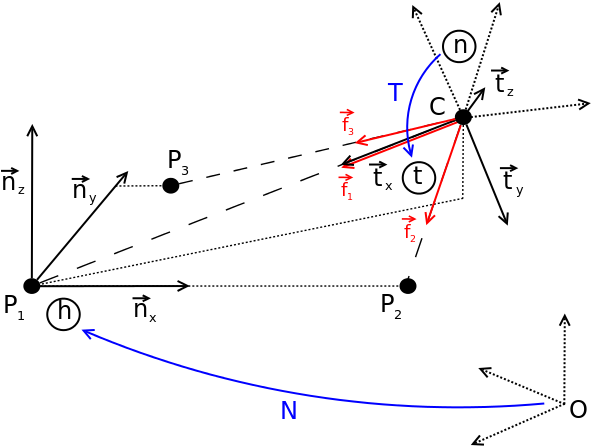
The Perspective-Three-Point (P3P) problem aims at determining the position and orientation of a camera in the world reference frame from three 2D-3D point correspondences. Most solutions attempt to first solve for the position of the points in the camera reference frame, and then compute the point aligning transformation between the camera and the world frame. In contrast, this work proposes a novel closed-form solution to the P3P problem, which computes the aligning transformation directly in a single stage, without the intermediate derivation of the points in the camera frame. This is made possible by introducing intermediate camera and world reference frames, and expressing their relative position and orientation using only two parameters. The projection of a world point into the parametrized camera pose then leads to two conditions and finally a quartic equation for finding up to four solutions for the parameter pair. A subsequent backsubstitution directly leads to the corresponding camera poses with respect to the world reference frame. The superior computational efficiency is particularly suitable for any RANSAC-outlier-rejection step, which is always recommended before applying PnP or non-linear optimization of the final solution.
Download C/C++ code (ZIP, 9 KB)
Author: Laurent Kneip
Reference
L. Kneip, D. Scaramuzza, R. Siegwart. A Novel Parameterization of the Perspective-Three-Point Problem for a Direct Computation of Absolute Camera Position and Orientation. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, USA, 2011. [ PDF (PDF, 269 KB) ]
OCamCalib: Omnidirectional Camera Calibration Toolbox for Matlab

Omnidirectional Camera Calibration Toolbox for Matlab (for Windows, MacOS, and Linux) for catadioptric and fisheye cameras up to 195 degrees.
Code, tutorials, and datasets can be found here.
Author: Davide Scaramuzza
Reference
D. Scaramuzza, A. Martinelli, R. Siegwart. A Toolbox for Easily Calibrating Omnidirectional Cameras. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2006), Beijing, China, October 2006. [ PDF (PDF, 1 MB) ]
D. Scaramuzza, A. Martinelli, R. Siegwart. A Flexible Technique for Accurate Omnidirectional Camera Calibration and Structure from Motion. IEEE International Conference on Computer Vision Systems (ICVS 2006), New York, USA, January 2006. [ PDF (PDF, 590 KB) ]