Distributed SPARQL querying with Avalanche

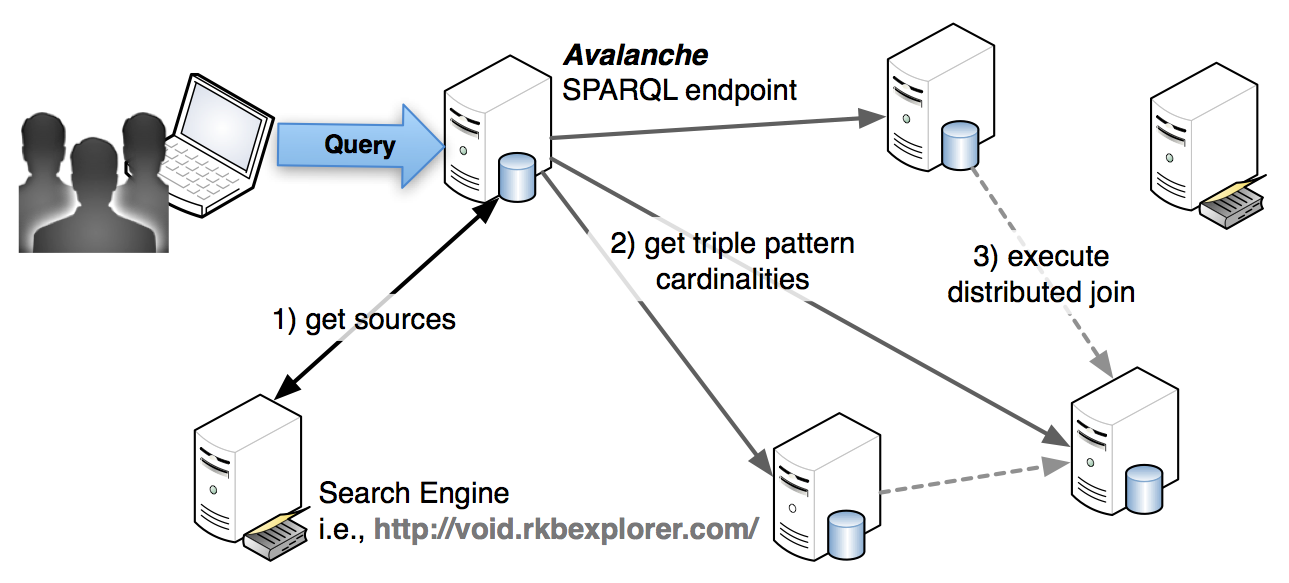
Avalanche is a system designed to allow a data surfer to query the Semantic Web transparently without making any prior assumptions about the data distribution, schema-alignment, pertinent data statistics, data evolution, and data presence (or accessibility of servers). Specifically, Avalanche can perform up-to-date (SPARQL) queries over the indexed Web of Data. Given a query it first gets on-line statistical information about potential data sources, the data distribution, as well as bandwidth availability. Then, it plans and executes the query in a distributed manner trying to quickly provide first answers.
We empirically evaluated Avalanche using a data-set consisting of 276 million triples (LUBM) distributed in different degrees of “messiness” over 100 servers as well as the Fedbench data-set
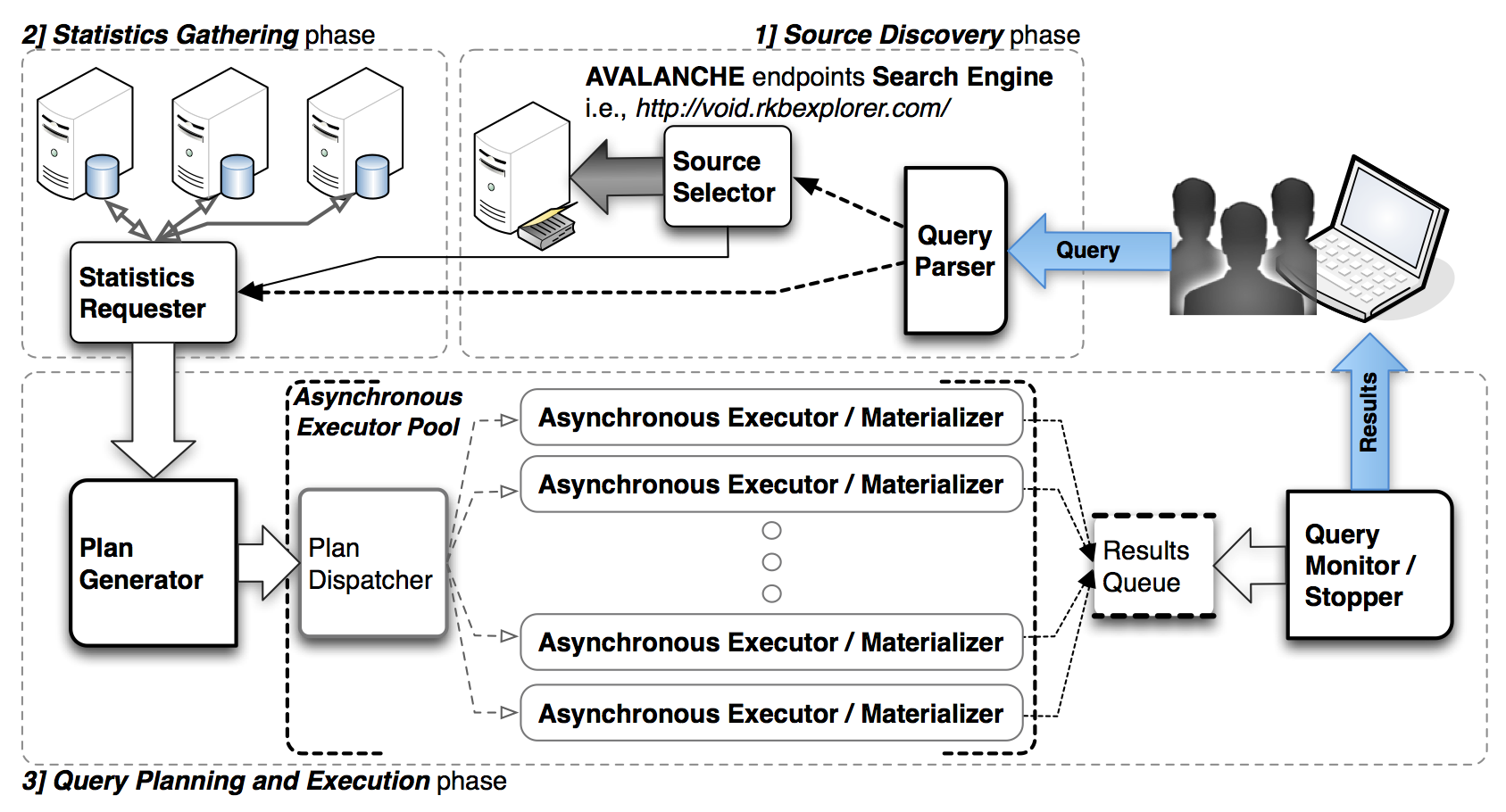
A simple view of the Avalanche execution model is ilustrated in the following figure (including the three major phases: a) source discovery, b) statistics gathering and c) distributed query execution):
engine is composed as follows:
Performance.The results of running the Fedbench benchmark on Avalanche vs a Baseline System:

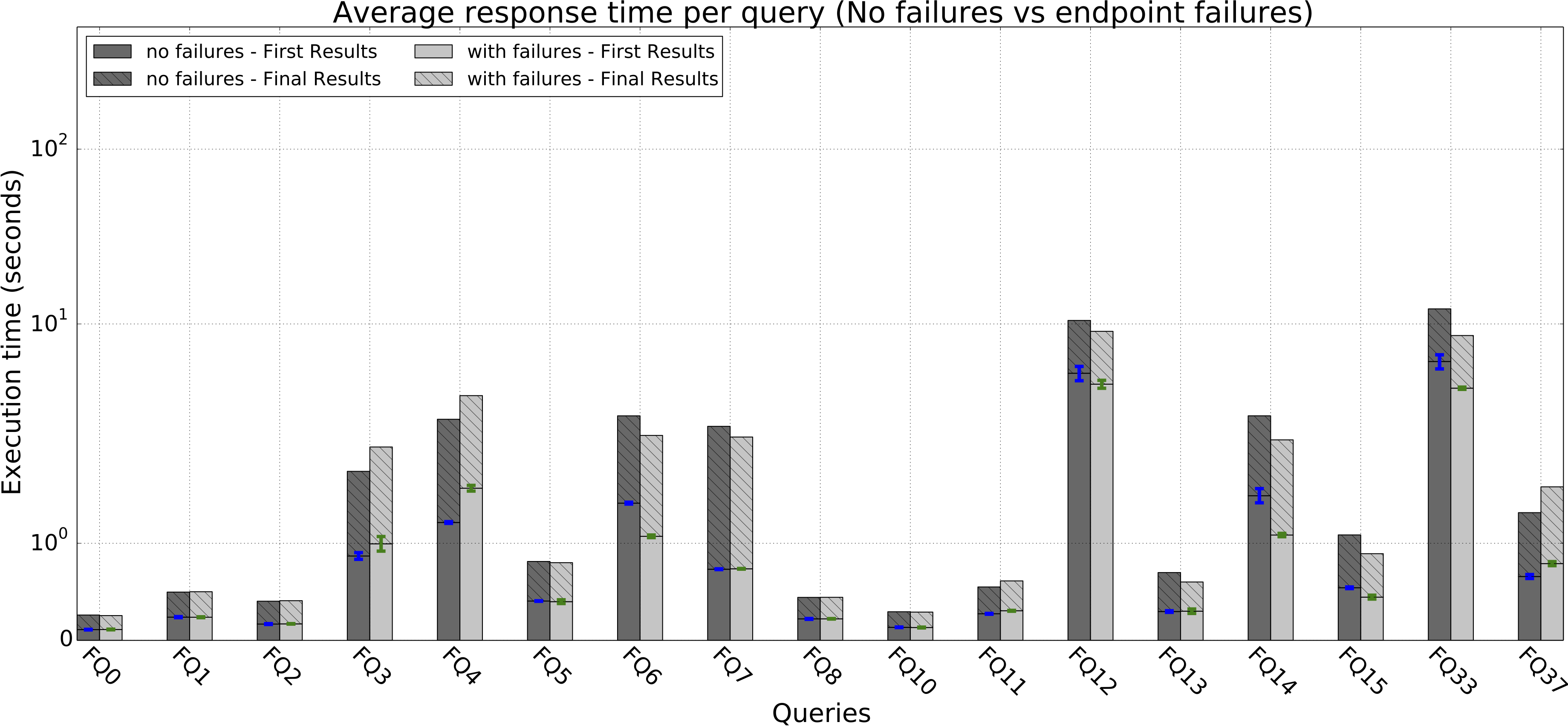
Fault Tolerance.The results of running a selection of the Fedbench benchmark on Avalanche when some sites fail vs. when no sites fail:
Related publications:
Querying a messy Web of Data with Avalanche, No. IFI-2013.03, Version: 1, 2013. (Technical Report). The latest work on Avalanche is currently a submission to the Journal of Web Semantics.
Additional resources:
Video describing Avalanche functionality:
You can download a poster (outdated) describing the Avalanche idea here: