UCCS Watchlist Challenge
3rd Open-set Face Detection and Identification Challenge held in conjunction with the IEEE International Joint Conference on Biometrics (IJCB 2024)
What's different?
In typical face detection or recognition datasets, the majority of images represent subjects who are aware of being photographed, or the images are deliberately chosen for public media. This means that blurry, occluded, or poorly illuminated images are infrequent or nonexistent in such datasets. Also, the majority of these challenges are characterized as closed-set, where the list of subjects in the gallery is identical to the one employed for probing.
However, the watchlist problem is a crucial application of face recognition systems, where the objective is to identify a few individuals listed on a watchlist while ignoring others. When applied in real-life surveillance, such as detecting criminals, many faces do not match anyone in the watchlist subjects, making open-set recognition necessary. Moreover, individuals in this scenario often remain unaware that their facial images are being recorded, so they do not cooperate with the system, which makes the identification of the watchlist subjects challenging.
We propose a challenge involving open-set face detection and identification, utilizing the UnConstrained College Students (UCCS) dataset. Through this challenge, our aim is to encourage research in face detection and recognition for surveillance applications, which are increasingly essential in today's context.
UnConstrained College Students (UCCS) Dataset
The UCCS dataset was collected over several months and comprises high-resolution images taken at the University of Colorado Colorado Springs, with the primary objective of recording individuals walking on a sidewalk from a considerable distance of 100–150 meters. The collection spanned 20 different days, ranging from February 2012 to September 2013, thereby providing a diverse array of images captured under various weather conditions, including sunny and snowy days. In addition, the presence of entities like sunglasses, winter caps, fur jackets, and frequent occlusions due to tree branches or poles add complexity to both detection and recognition tasks.


Two images from the UCCS dataset, including small to large occlusions, significant yaw and pitch angles, and instances of significant blur.
In the data-cleaning period, the UCCS dataset underwent a series of enhancements for improved quality and size. Initially, only fully visible faces were labeled, and severely occluded faces were later included. Subsequently, the application of facial landmark localization algorithms facilitated the definition of new bounding boxes for all faces. This refinement aimed to provide clearer face bounding box definitions, enabling the use of default IoU metrics for standardized evaluation. Despite these efforts in the preceding steps, challenges remained, resulting in some mislabeled faces due to the difficulties in the labeling process. These inaccuracies included cases in which faces within a particular identity were mismatched or identity was erroneously labeled with different identity labels. To address this, a recent step involved intra-class and inter-class search, utilizing a combination of semi-automated and manual methods to rectify mislabeled faces. All these rigorous processes were implemented to uphold the accuracy and reliability of the dataset. Consequently, the new version of the UCCS dataset consists of more than 85000 faces in total. Dataset images are in JPG format with an average size of 5184 × 3456.
In contrast to prior invocations of this competition, this year's challenge introduces a watchlist, which comprises cropped expanded face regions from the dataset, eliminating the need for a traditional training set. The selection of watchlist identities follows some criteria such as prioritizing high-quality faces, coming from the same sequence, and including all identities that appear in multiple sequences. Following these constraints, a selection process resulted in choosing precisely 1000 different identities that will be treated as knowns and make up our gallery. About 40% of these identities appear over two or more days. Each identity in the gallery is represented by 10 different faces, with accompanying information on the positions of 5 facial landmarks, including the eyes, nose, and mouth.


An identity in the watchlist: the left represents the gallery face, while the right shows 5 facial landmarks that will be provided.
Following the completion of the gallery, we split up the UCCS dataset into validation and test sets. The validation set, accessible to participants at the competition's onset, includes annotated images with lists of bounding boxes. Each bounding box is assigned either an integral gallery identity label or the unknown label "-1". The UCCS test set will solely consist of raw images with anonymized file names, devoid of any annotations. In both sets, about half of the faces are categorized as "unknown" to emulate real-world scenarios, including the remaining identities that are not enrolled in the gallery, and faces that are left with the unknown label in our dataset.


The left one shows an annotated image (not real values) from the dataset, while the right one displays the sequence of some known identities, representing diverse poses and degrees of blurriness.
This challenge involves two distinct tasks, detailed in subsequent sections. Participants are granted the flexibility to train their models or optimize the meta-parameters of their algorithms using the watchlist (gallery) / validation set. Additionally, they are also free to incorporate external training data if desired.
Protocol Files
All protocol files are given in CSV format. In the watchlist (gallery), the faces of the identities, consisting of only known 1000 different subjects, are cropped from the UCCS database. The gallery protocol file comprehensively details the information regarding each face of identity within the cropped area, encompassing a positive integral SUBJECT_ID and the positions of manually labeled 5 facial landmarks (eyes, nose, and mouth). The validation protocol file particularly contains a unique number (FACE_ID), the image file name, subject ID (which might be -1 for unknown identities), and hand-labeled face bounding box annotations. In contrast, the test set's protocol file solely consists of a list of file names without any accompanying information about the face(s) within the images. The examples provided below illustrate the structure of the protocol files, not representing actual data.
Gallery (Watchlist) Protocol
| FILE | SUBJECT_ID | REYE_X | REYE_Y | LEYE_X | LEYE_Y | NOSE_X | NOSE_Y | RMOUTH_X | RMOUTH_Y | LMOUTH_X | LMOUTH_Y |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0001_0.png | 0001 | 197.24 | 218.55 | 264.87 | 220.10 | 215.33 | 269.67 | 211.23 | 301.12 | 301.11 | 313.43 |
| 0001_1.png | 0001 | 155.76 | 201.13 | 243.15 | 189.99 | 211.78 | 252.12 | 174.12 | 302.65 | 231.87 | 298.59 |
| 0001_2.png | 0001 | 162.22 | 219.97 | 244.91 | 223.14 | 195.52 | 268.71 | 165.36 | 297.48 | 222.54 | 293.16 |
Validation Protocol
| FILE | FACE_ID | SUBJECT_ID | FACE_X | FACE_Y | FACE_WIDTH | FACE_HEIGHT |
|---|---|---|---|---|---|---|
| a0t85e794b56df6e36a1a8b5ucf23d71.jpg | 10213 | 835 | 2422.5 | 1995.5 | 221.7 | 311.6 |
| a0t85e794b56df6e36a1a8b5ucf23d71.jpg | 43213 | 627 | 2820.6 | 3046.1 | 202.1 | 245.9 |
| a0t85e794b56df6e36a1a8b5ucf23d71.jpg | 31130 | -1 | 856.0 | 1312.4 | 124.1 | 143.5 |
Test Protocol
| FILE |
|---|
| 0202b2be7atc9531m73bcxe60c4af6fd.jpg |
| 42arb2bb9531m5243jgsnsvvsa01p98e.jpg |
| gs489gfjhanz0hj8jgmzpriq241ka491.jpg |
Challenge
This challenge is divided into two separate tasks detailed in the bulleted list below: (I) face detection and (II) open-set face recognition. Participants have the freedom to select either of the tasks, although they are encouraged to contribute to both tasks if possible. Both score files for these two tasks are expected in CSV format.
- In Part (I), the participants are tasked with enumerating all detected faces (independent of the identity label) in the UCCS dataset images. For each image in the UCCS test set, they are required to submit a list of detected faces along with their respective face detection scores. Detection scores should fall within the range of 0 to 1, where higher scores indicate greater confidence. For a streamlined evaluation process, contributors should supply the score file with a specified format. This desired face detection score file is shown below. Note that generally there is more than one bounding box per image file. Hence, there should be several lines for each image.
- Part (II) of the challenge conducts experiments focusing on face detection and open-set face identification, where test images contain faces with known and unknown identities. Participants have the flexibility to construct their gallery using the provided enrollment faces. For probe images, they are required to compute cosine similarities of each detected bounding box from Part (I) with each of the watchlist (gallery) subjects. Higher similarity scores, ranging between -1 and 1, indicate a stronger likelihood that the identity of the detected bounding box will be assigned to the corresponding subject in the gallery. To facilitate a more efficient evaluation process, it is essential to provide the score file in a specified format. The face identification score file is an extension of the face detection score file, including the similarity score of each identity in the gallery. The required format for the face identification score file is demonstrated below.
Lastly, the submission of the final score file(s) of the test set will be carried out by sending it to this email. If you plan to participate in both challenges, the face identification score file can be used for evaluating both the detection and the recognition experiment. Therefore, only one score file needs to be submitted in this case. Encouraged to submit results for both tasks, participants will undergo evaluation conducted by the challenge organizers.
Face Detection Score File
| FILE | DETECTION_SCORE | BB_X | BB_Y | BB_WIDTH | BB_HEIGHT |
|---|---|---|---|---|---|
| 0202b2be7atc9531m73bcxe60c4af6fd.jpg | 0.86 | 143.17 | 3133.68 | 83.25 | 96.89 |
| 0202b2be7atc9531m73bcxe60c4af6fd.jpg | 0.75 | 1294.67 | 2531.15 | 101.6 | 178.2 |
| 0202b2be7atc9531m73bcxe60c4af6fd.jpg | 0.65 | 2287.34 | 1276.14 | 120.4 | 156.5 |
Face Identification Score File
| FILE | DETECTION_SCORE | BB_X | BB_Y | BB_WIDTH | BB_HEIGHT | S_0001 | S_0002 | ... | ... | S_0999 | S_1000 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0202b2be7atc9531m73bcxe60c4af6fd.jpg | 0.86 | 143.17 | 3133.68 | 83.25 | 96.89 | 0.20341 | 0.023113 | ... | ... | 0.103141 | 0.000213 |
| 0202b2be7atc9531m73bcxe60c4af6fd.jpg | 0.75 | 1294.67 | 2531.15 | 101.6 | 178.2 | 0.00213 | 0.019521 | ... | ... | 0.45982 | 0.12019 |
| 0202b2be7atc9531m73bcxe60c4af6fd.jpg | 0.65 | 2287.34 | 1276.14 | 120.4 | 156.5 | 0.000211 | 0.093211 | ... | ... | 0.32118 | 0.11095 |
Baseline
The baseline face detection and face recognition experiments are published as an open-source Python Package using an open-source machine learning (ML) framework, PyTorch. You can download the baseline package from PyPI or the GitHub repository. This package contains various scripts capable of executing open-source baseline algorithms for both tasks so that contributors' model performances can be compared to the baseline. In addition to incorporating these baseline algorithms into the package, it facilitates the generation of desired score files, which will subsequently go through evaluation. In simpler terms, participants can effortlessly execute these baseline algorithms for the designated tasks. They can then generate score files of their methods in the specified format and proceed to run the evaluation. Please refer to the baseline package for more details.
The baseline face detector simply uses the pre-trained MTCNN, with the Pytorch implementation. Since the detector is not optimized for blurry, occluded, or full-profile faces, we had to lower the three detection thresholds to (0.2, 0.2, 0.2), but also provide many background detections. For face identification, detected faces are first cropped and then aligned to run the feature extractor. Following this, face features with the shape of (,512) are extracted by a cutting-edge method,pre-trained MagFace with the backbone of iResNet100. For enrollment, we average the features over the 10 faces per subject in the watchlist and compare probe faces and gallery templates via cosine similarity. If you do not wish to run the baseline face detection/ identification algorithms, we will provide the baseline score files for the validation set alongside the dataset when shared.
Evaluation
The organizers of the challenge will conduct evaluations on the submitted score files in the specified format. Each task will be assessed using a distinct plot to compare the results of all participants. The details of these plots are explained separately for each task.
- In the evaluation of face detectors, the number of allowed face detections per image will be restricted, and false positives will be penalized. The evaluation will be based on the Free Receiver Operating Characteristics (FROC) curve to present and analyze the results. Instead of computing False Detection Rates, we evaluate the number of False Detections Per Image, which is calculated by dividing the misdetections by the number of probe images. As common, the vertical axis shows the Detection Rate (true positive rate).
- During the evaluation of face recognition models, faces will be either assigned to an identity or rejected based on these similarity scores. Providing high scores for unknown identities or misdetections, which indicate a false match with a watchlist identity, will result in penalties. The evaluation will utilize a modified version of the Detection and Identification Rate (DIR) curve on rank 1, also known as the Open-Set ROC curve that computes True Positive Identification Rates (TPIR) over False Positive Identification Rates (FPIR). Since the false alarm axis is dependent on the number of detected faces, we make slight modifications to this axis by dividing it by the number of probe images, leading to the False Positive Identification per Image. This FPI per Image axis is in a logarithmic scale, representing non-rejected unknown faces and misdetections.
An implementation of the evaluation for the validation set is provided in the baseline package. Please refer to this package for more details about the evaluation. The evaluation curves for the baseline algorithms mentioned above are presented for the validation set.
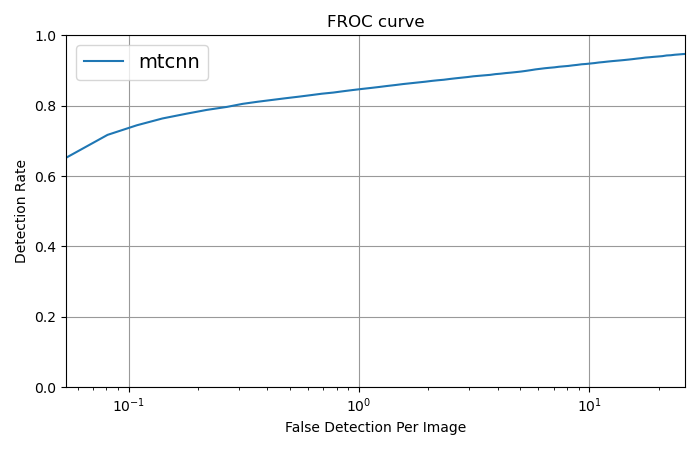
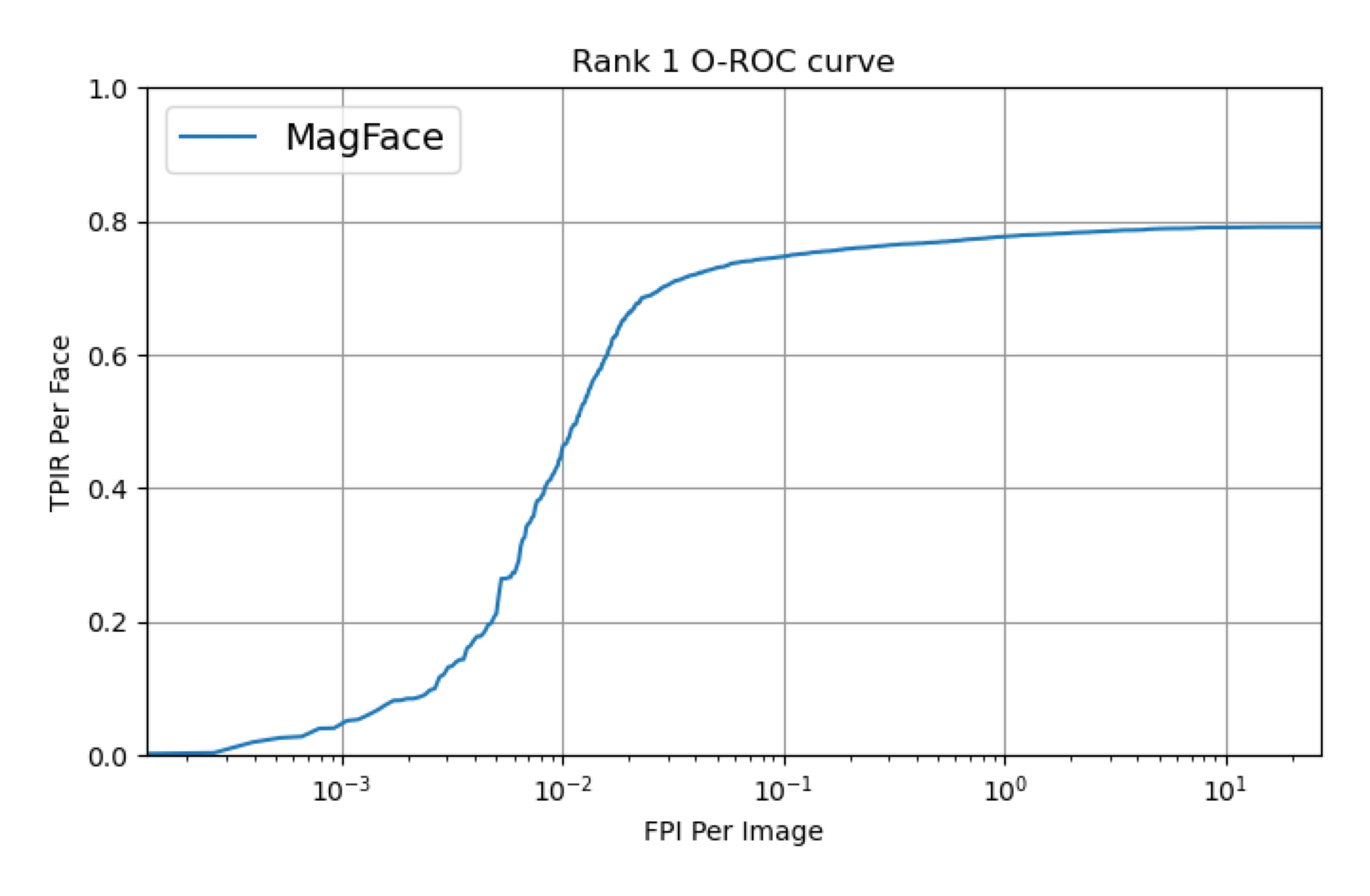
The evaluation of baseline algorithms on the validation set.
Registration
We extend a warm welcome to academic and commercial participants to join and engage in the competition. The registration will be open by March 1, 2024. To register, all required information should be sent to this e-mail with the email subject “Application for UCCS Watchlist Challenge”. The email should include the following information to facilitate the selection process:
- A webpage link of the participant, representing a certain senior level in this field.
- Specify which task(s) you intend to work on.
- By accessing and using the data provided for this challenge, you explicitly acknowledge and agree to all terms and conditions specified in the UCCS Database License (TXT, 9 KB). If you do not agree, you are not permitted to use the provided data.
Accepted participants will have all necessary files (watchlist, validation set, and protocol files ) via a link and password provided by organizers. The images from the test set without any annotations will be made available two weeks before the final day of the challenge. Registration will remain open until the day when the test set is released.
Important Dates
- March 1, 2024: Open registration, and the release of challenge data (gallery and validation) and baseline package
- May 15, 2024 :
Close registrationand test data release without any annotations - May 22, 2024 : Close registration
- June 1, 2024 : Submission deadline of the score file(s) and brief descriptions of particpants' algorithms
- June 30, 2024: Submission deadline for the summary paper