Interactive Visual Data Labeling

Introduction
The assignment of labels to data instances is a fundamental prerequisite for most supervised machine learning tasks and constitutes one of the main bottlenecks in many machine learning approaches.
Data labeling is typically conducted by humans, which can be tedious and error-prone, especially if the required training dataset is large. In many real-world applications, user groups in research and industry urgently need more effective labeling approaches, as a prerequisite to start building their own machine learning solution. A variety of types of data instances exist that require labels, including images, audio, time series and event sequences, text documents. Also, the characteristics of label alphabets can vary considerably: from binary labels (true/false), over multi-class alphabets (Apples, Oranges, etc.) to label hierarchies, such as the 17 SDG goals and sub-categories.
We study the process of labeling data instances with the user in the loop, from both the machine learning (leveraging active learning) and the interactive and visual perspective (enabling humans to select instances by themselves). Our research builds upon our methodology “visual interactive labeling” (VIAL), which unifies both perspectives. VIAL describes the six major steps of the process and discusses their specific challenges.
The VIAL Process, as proposed by Bernard et al.
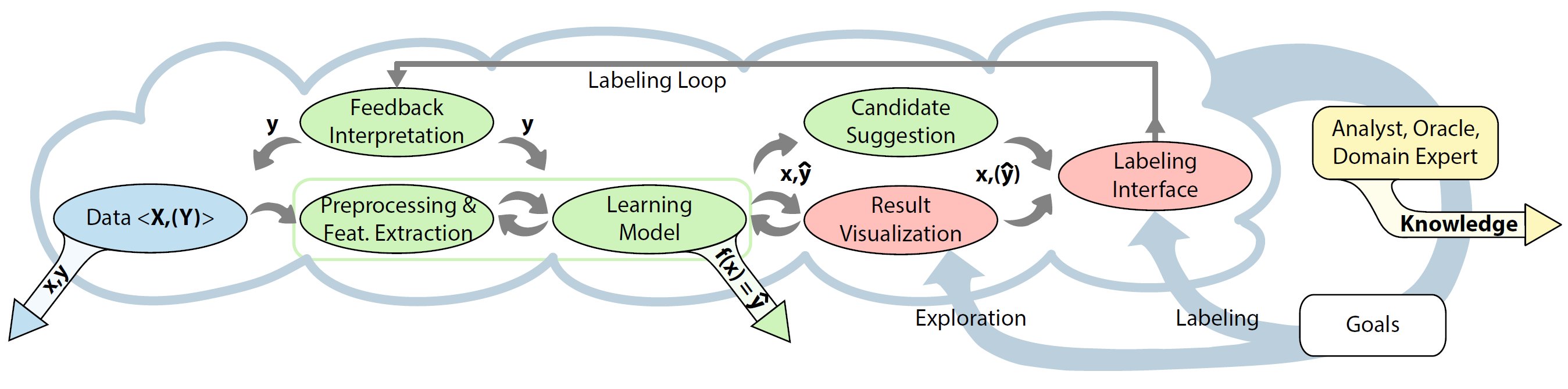
The VIAL process. Four algorithmic models (green) and two primary visual interfaces (red) are assembled to an iterative labeling process. To resemble the special characteristics of the Active Learning and the Visualization perspective, the VIAL process contains a branch (from "Learning Model” to “candidate suggestion” and “result visualization,” since both are complementary). The VIAL process can be applied for data exploration and labeling tasks. The output of the VIAL process is threefold: labeled data, learned models, and gained knowledge.
Selection of Instances for Labeling by Machines and Humans
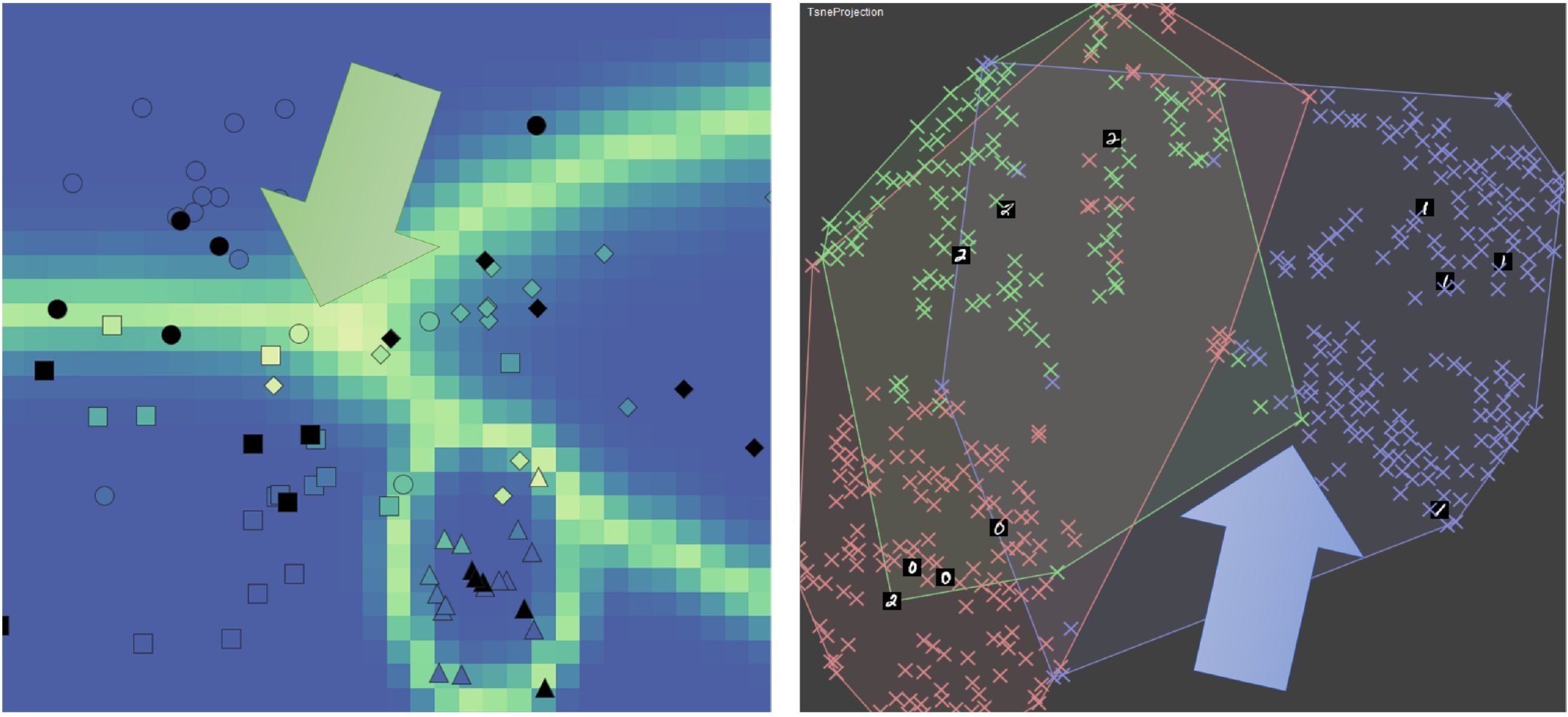
Complementary strengths of model-based and user-based instance selection for data labeling. Left: visualization that explains the decision boundaries of a classifier using bright colors. Uncertainty-based AL strategies (model-based) will select instances near the decision boundaries. Right: visualization that explains the prediction of a classifier for unlabeled data (colors). Users selecting instances may want to resolve the local green class confusion.
Application Example: Labeling Publications by Sustainability Goals
.png)
The 17 SDG goals form an interesting machine learning task that we want to study as one representative labeling application: can we effectively identify sustainability contributions in scientific publications? For that purpose, an AI component will be fed with a growing training dataset of scientific publications; this training dataset will interactively and iteratively be extended with additional labeled publications, as the result of a human-machine collaboration approach.
Publication: DaedalusData: Exploration, Knowledge Externalization and Labeling of Particles in Medical Manufacturing

In medical diagnostics of both early disease detection and routine patient care, particle-based contamination of in-vitro diagnostics consumables poses a significant threat to patients. Objective data-driven decision-making on the severity of contamination is key for reducing patient risk, while saving time and cost in quality assessment. Our collaborators introduced us to their quality control process, including particle data acquisition through image recognition, feature extraction, and attributes reflecting the production context of particles. Shortcomings in the current process are limitations in exploring thousands of images, data-driven decision-making, and ineffective knowledge externalization. Following the design study methodology, our contributions are a characterization of the problem space and requirements, the development and validation of DaedalusData, a comprehensive discussion of our study’s learnings, and a generalizable framework for knowledge externalization. DaedalusData is a visual analytics system that enables domain experts to explore particle contamination patterns, label particles in label alphabets, and externalize knowledge through semi-supervised label-informed data projections. The results of our case study and user study show high usability of DaedalusData and its efficient support of experts in generating comprehensive overviews of thousands of particles, labeling of large quantities of particles, and externalizing knowledge to augment the dataset further. Reflecting on our approach, we discuss insights on dataset augmentation via human knowledge externalization, and on the scalability and trade-offs that come with the adoption of this approach in practice.

The DaedalusData framework supports two control modes for experts to steer the particle display with, shown here as a 2×2 matrix. Vertical: Experts choose between the Attribute View (for one attribute) and the Projection View (for multiple user-specified attributes) to identify areas of interest, and discover similar particles to label. Horizontal: Experts choose to explore either the Pre-Existing Data Attributes (the Image & Production Context), or to extend the exploration to Augmented Data Attributes created through particle labeling (Expert Knowledge). This design study implements a systematic cross-cut of all four types of control, addressing expert-contributed design requirements (seen as (Rn) in the figure). DaedalusData enables experts to conduct two core workflows: Data Exploration and Labeling (Flow 1), and its extension, Knowledge Externalization (Flow 2). On the right, we introduce four Auxiliary Views that perform labeling, and facilitate interactive drill-downs, particle selection, and detailed analysis .
Publications
The IVDA group members have more than 20 publications in the VIAL realm. A hub with pointers to individual Visual-Interactive Labeling (VIAL) papers can be found here.