Deep Learning
Deep learning is a branch of machine learning based on a set of algorithms that attempt to model high level abstractions in data. In our research, we apply deep learning to solve different mobile robot navigation problems, such as depth estimation, end-to-end navigation, and classification.
End-to-End Learning of Representations for Asynchronous Event-Based Data
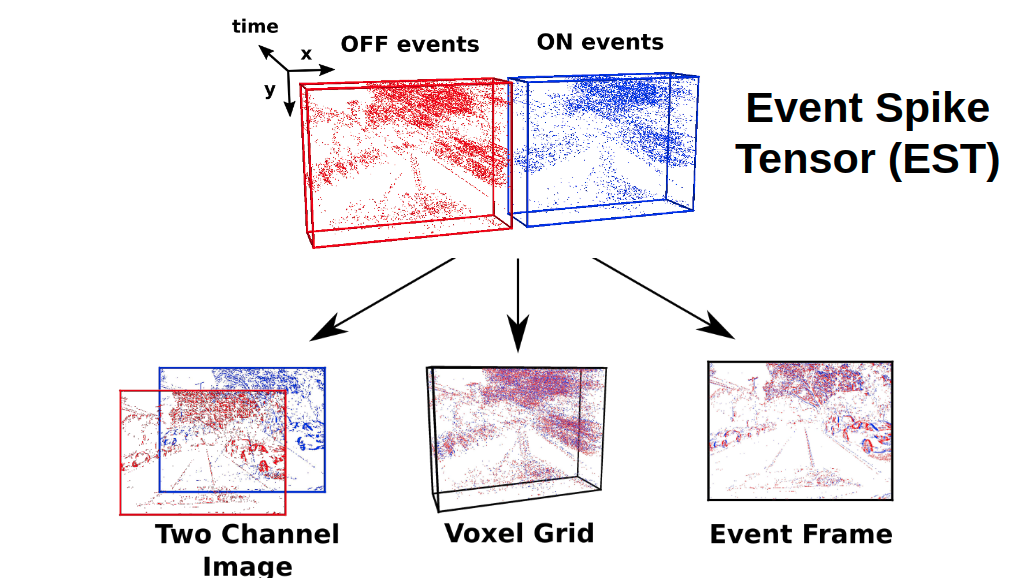
Event cameras are vision sensors that record asynchronous streams of per-pixel brightness changes, referred to as "events". They have appealing advantages over frame-based cameras for computer vision, including high temporal resolution, high dynamic range, and no motion blur. Due to the sparse, non-uniform spatiotemporal layout of the event signal, pattern recognition algorithms typically aggregate events into a grid-based representation and subsequently process it by a standard vision pipeline, e.g., Convolutional Neural Network (CNN). In this work, we introduce a general framework to convert event streams into grid-based representations through a sequence of differentiable operations. Our framework comes with two main advantages: (i) allows learning the input event representation together with the task dedicated network in an end to end manner, and (ii) lays out a taxonomy that unifies the majority of extant event representations in the literature and identifies novel ones. Empirically, we show that our approach to learning the event representation end-to-end yields an improvement of approximately 12% on optical flow estimation and object recognition over state-of-the-art methods.
References
|
|
D. Gehrig, A. Loquercio, K. G. Derpanis, D. Scaramuzza End-to-End Learning of Representations for Asynchronous Event-Based Data (Under review) |
Beauty and the Beast: Optimal Methods Meet Learning for Drone Racing

Autonomous micro aerial vehicles still struggle with fast and agile maneuvers, dynamic environments, imperfect sensing, and state estimation drift. Autonomous drone racing brings these challenges to the fore. Human pilots can fly a previously unseen track after a handful of practice runs. In contrast, state-of-the-art autonomous navigation algorithms require either a precise metric map of the environment or a large amount of training data collected in the track of interest. To bridge this gap, we propose an approach that can fly a new track in a previously unseen environment without a precise map or expensive data collection. Our approach represents the global track layout with coarse gate locations, which can be easily estimated from a single demonstration flight. At test time, a convolutional network predicts the poses of the closest gates along with their uncertainty. These predictions are incorporated by an extended Kalman filter to maintain optimal maximum-a-posteriori estimates of gate locations. This allows the framework to cope with misleading high-variance estimates that could stem from poor observability or lack of visible gates. Given the estimated gate poses, we use model predictive control to quickly and accurately navigate through the track. We conduct extensive experiments in the physical world, demonstrating agile and robust flight through complex and diverse previously-unseen race tracks. The presented approach was used to win the IROS 2018 Autonomous Drone Race Competition, outracing the second-placing team by a factor of two.
References
|
|
E. Kaufmann, M. Gehrig, P. Foehn, R. Ranftl, A. Dosovitskiy, V. Koltun, D. Scaramuzza Beauty and the Beast: Optimal Methods Meet Learning for Drone Racing (Under review) |
Deep Drone Racing: Learning Agile Flight in Dynamic Environments

Autonomous agile flight brings up fundamental challenges in robotics, such as coping with unreliable state estimation, reacting optimally to dynamically changing environments, and coupling perception and action in real time under severe resource constraints. In this paper, we consider these challenges in the context of autonomous, vision-based drone racing in dynamic environments. Our approach combines a convolutional neural network (CNN) with a state-of-the-art path-planning and control system. The CNN directly maps raw images into a robust representation in the form of a waypoint and desired speed. This information is then used by the planner to generate a short, minimum-jerk trajectory segment and corresponding motor commands to reach the desired goal. We demonstrate our method in autonomous agile flight scenarios, in which a vision-based quadrotor traverses drone-racing tracks with possibly moving gates. Our method does not require any explicit map of the environment and runs fully onboard. We extensively test the precision and robustness of the approach in simulation and in the physical world. We also evaluate our method against state-of-the-art navigation approaches and professional human drone pilots.
References
|
|
E. Kaufmann, A. Loquercio, R. Ranftl, A. Dosovitskiy, V. Koltun, D. Scaramuzza Deep Drone Racing: Learning Agile Flight in Dynamic Environments Conference on Robotic Learning (CoRL), Zurich, 2018. Best Systems Paper Award. Oral presentation. |
Smart Interest Points
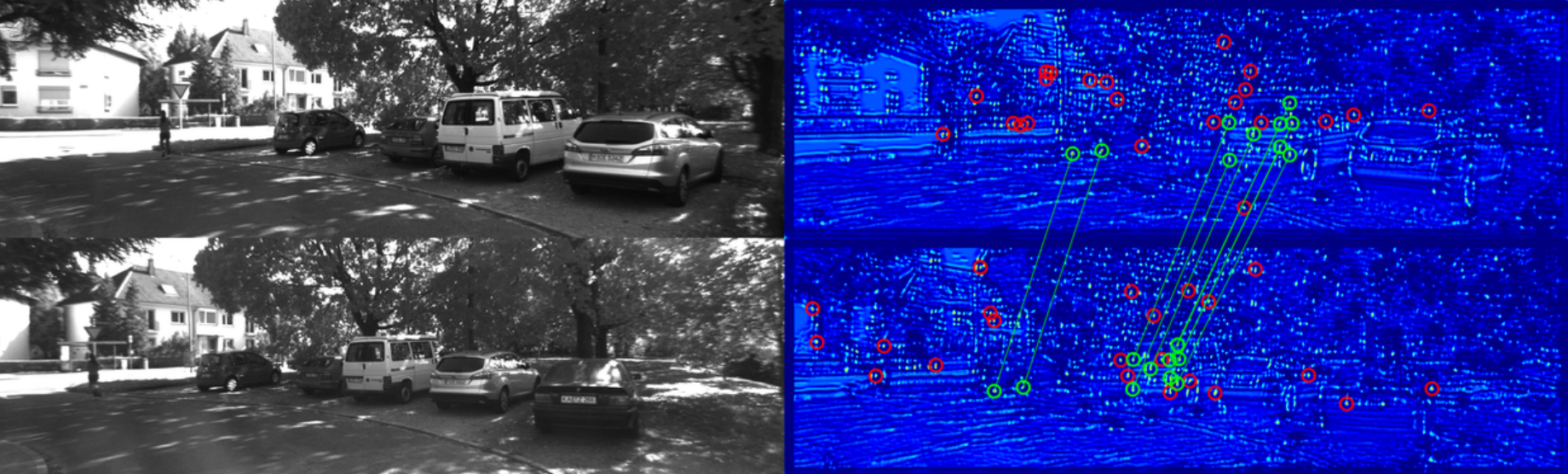
Detecting interest points is a key component of vision-based estimation algorithms, such as visual odometry or visual SLAM. In the context of distributed visual SLAM, we have encountered the need to minimize the amount of data that is sent between robots, which, for relative pose estimation, translates into the need to find a minimum set of interest points that is sufficiently reliably detected between viewpoints to ensure relative pose estimation. We have decided to solve this problem at a fundamental level, that is, at the point detector, using machine learning.
In SIPS, we introduce the succinctness metric, which allows to quantify performance of interest point detectors with respect to this goal. At the same time, we propose an unsupervised training method for CNN interest point detectors which requires no labels - only uncalibrated image sequences. The proposed method is able to establish relative poses with a minimum of extracted interest points. However, descriptors still need to be extracted and transmitted to establish these poses.
This problem is addressed in IMIPs, where we propose the first feature matching pipeline that works by implicit matching, without the need of descriptors. In IMIPs, the detector CNN has multiple output channels, and each channel generates a single interest point. Between viewpoints, interest points obtained from the same channel are considered implicitly matched. This allows matching points with as little as 3 bytes per point - the point coordinates in an up to 4096 x 4096 image.
References
|
|
T. Cieslewski, M. Bloesch, D. Scaramuzza Matching Features without Descriptors: arXiv (November 2018) |
|
|
T. Cieslewski, D. Scaramuzza SIPS: Unsupervised Succinct Interest Points
arXiv (May 2018) |


Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Cars
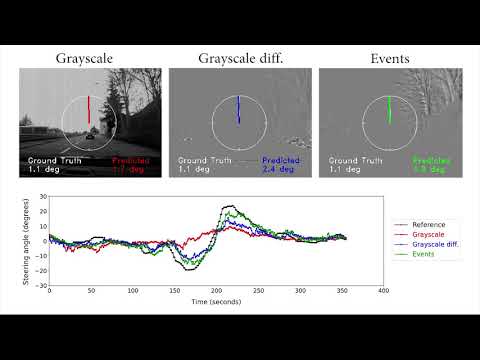
Event cameras are bio-inspired vision sensors that naturally capture the dynamics of a scene, filtering out redundant information. This paper presents a deep neural network approach that unlocks the potential of event cameras on a challenging motion-estimation task: prediction of a vehicle's steering angle. To make the best out of this sensor-algorithm combination, we adapt state-of-the-art convolutional architectures to the output of event sensors and extensively evaluate the performance of our approach on a publicly available large scale event-camera dataset (~1000 km). We present qualitative and quantitative explanations of why event cameras allow robust steering prediction even in cases where traditional cameras fail, e.g. challenging illumination conditions and fast motion. Finally, we demonstrate the advantages of leveraging transfer learning from traditional to event-based vision, and show that our approach outperforms state-of-the-art algorithms based on standard cameras.
References
|
|
Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Cars IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, 2018. |

DroNet: Learning to Fly by Driving

Civilian drones are soon expected to be used in a wide variety of tasks, such as aerial surveillance, delivery, or monitoring of existing architectures. Nevertheless, their deployment in urban environments has so far been limited. Indeed, in unstructured and highly dynamic scenarios drones face numerous challenges to navigate autonomously in a feasible and safe way. In contrast to the traditional map-localize-plan methods, this paper explores a data-driven approach to cope with the above challenges. To do this, we propose DroNet, a convolutional neural network that can safely drive a drone through the streets of a city. Designed as a fast 8-layers residual network, DroNet produces, for each single input image, two outputs: a steering angle, to keep the drone navigating while avoiding obstacles, and a collision probability, to let the UAV recognize dangerous situations and promptly react to them. But how to collect enough data in an unstructured outdoor environment, such as a city? Clearly, having an expert pilot providing training trajectories is not an option given the large amount of data required and, above all, the risk that it involves for others vehicles or pedestrians moving in the streets. Therefore, we propose to train a UAV from data collected by cars and bicycles, which, already integrated into urban environments, would expose other cars and pedestrians to no danger. Although trained on city streets, from the viewpoint of urban vehicles, the navigation policy learned by DroNet is highly generalizable. Indeed, it allows a UAV to successfully fly at relative high altitudes, and even in indoor environments, such as parking lots and corridors.
References
|
|
DroNet: Learning to Fly by Driving IEEE Robotics and Automation Letters (RA-L), 2018. |
Place Recognition in Semi-Dense Maps: Geometric and Learning-Based Approaches

For robotics and augmented reality systems operating in large and dynamic environments, place recognition and tracking using vision represent very challenging tasks. Additionally, when these systems need to reliably operate for very long time periods, such as months or years, further challenges are introduced by severe environmental changes, that can significantly alter the visual appearance of a scene. Thus, to unlock long term, large scale visual place recognition, it is necessary to develop new methodologies for improving localization under difficult conditions. As shown in previous work, gains in robustness can be achieved by exploiting the 3D structural information of a scene. The latter, extracted from image sequences, carries in fact more discriminative clues than individual images only. In this paper, we propose to represent a scene's structure with semi-dense point clouds, due to their highly informative power, and the simplicity of their generation through mature visual odometry and SLAM systems. Then we cast place recognition as an instance of pose retrieval and evaluate several techniques, including recent learning based approaches, to produce discriminative descriptors of semi-dense point clouds. Our proposed methodology, evaluated on the recently published and challenging Oxford Robotcar Dataset, shows to outperform image-based place recognition, with improvements up to 30% in precision across strong appearance changes. To the best of our knowledge, we are the first to propose place recognition in semi-dense maps.
References
|
|
Place Recognition in Semi-Dense Maps: Geometric and Learning-Based Approaches British Machine Vision Conference (BMVC), London, 2017. |
Learning-based Image Enhancement for Visual Odometry in Challenging HDR Environments
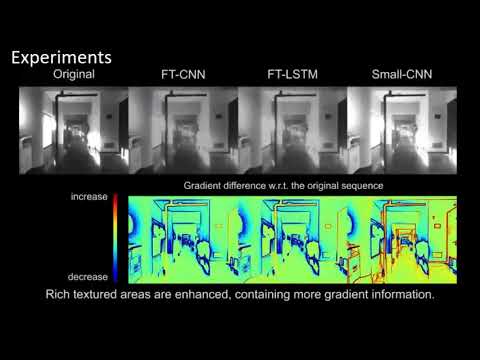
One of the main open challenges in visual odometry (VO) is the robustness to difficult illumination conditions or high dynamic range (HDR) environments. The main difficulties in these situations come from both the limitations of the sensors and the inability to perform a successful tracking of interest points because of the bold assumptions in VO, such as brightness constancy. We address this problem from a deep learning perspective, for which we first fine-tune a Deep Neural Network (DNN) with the purpose of obtaining enhanced representations of the sequences for VO. Then, we demonstrate how the insertion of Long Short Term Memory (LSTM) allows us to obtain temporally consistent sequences, as the estimation depends on previous states. However, the use of very deep networks does not allow the insertion into a real-time VO framework; therefore, we also propose a Convolutional Neural Network (CNN) of reduced size capable of performing faster. Finally, we validate the enhanced representations by evaluating the sequences produced by the two architectures in several state-of-art VO algorithms, such as ORB-SLAM and DSO.
References
|
|
Learning-based Image Enhancement for Visual Odometry in Challenging HDR Environments IEEE International Conference on Robotics and Automation (ICRA), 2018. |

Towards Domain Independence for Learning-Based Monocular Depth Estimation
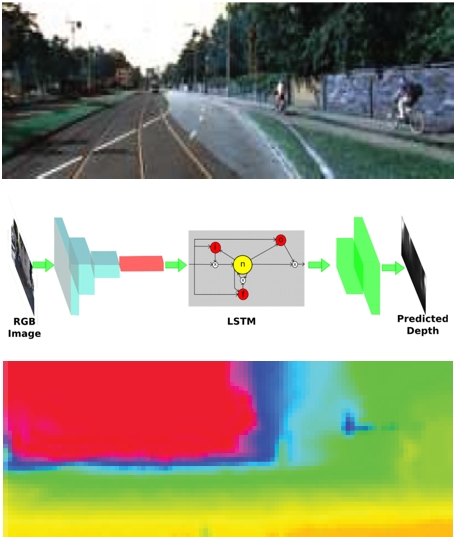
References
|
|
Towards Domain Independence for Learning-Based Monocular Depth Estimation IEEE Robotics and Automation Letters (RA-L), 2017. |
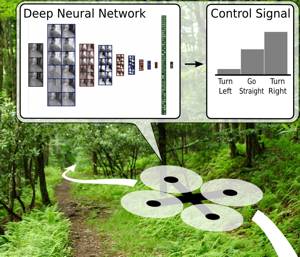
A Deep Learning Approach for Automatic Recognition and Following of Forest Trails with Drones

References
|
|
A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots IEEE Robotics and Automation Letters (RA-L), 2016. Nominated for AAAI Best Video Award! |
"On-the-spot Training" for Terrain Classification in Autonomous Air-Ground Collaborative Teams

References
|
|
"On-the-spot Training" for Terrain Classification in Autonomous Air-Ground Collaborative Teams International Symposium on Experimental Robotics (ISER), Tokyo, 2016. |
