Navigation auf uzh.ch
Navigation auf uzh.ch

Successful software systems must change or they become progressively less useful, but as they evolve, they become more complex and consequently more resources are needed to preserve and simplify their structure. Studies estimate the costs for the maintenance and evolution of large, complex software systems from 50% to 95% of the total costs in the software life-cycle. To reduce these costs several techniques and tools have been developed: to discover components that need to be modified when a new feature is integrated, to detect architectural shortcomings, or for project managers to estimate the maintenance costs and allow for better planning.
These software analysis tools focus on just a particular kind of analysis to produce the results wanted by the engineer. For every required analysis, a specialized tool, with its own explicit or implicit meta-model dictating how to represent the input and the output, has to be installed, configured and executed. Thus the sharing of information between tools is only possible by means of a cumbersome export towards files complying to a specified exchange format. Even if different analyses of the same kind exist, there is no way to compare their results or integrate them other than manual investigation. Tool interoperability is hampered even more by their stand-alone nature, as well as their platform and language dependence.
Thus, the combination and integration of different software analysis tools is a challenging problem when we need to gain a deeper insight into a software system evolution. We claim that this status quo severely hampers software evolution research and a critical assessment of the research fields uncovers the fact that people keep re-inventing the same wheels with little advancement of the field as a whole.
SOFAS' (SOFware Analysis Services) purpose is to solve this problem by devising a distributed and collaborative software analysis platform to allow for interoperability of software analysis tools across platform, geographical and organizational boundaries. Such tools are mapped into a software analysis taxonomy and adhere to specific meta-models and ontologies for their category of analysis and offer a common service interface that enables their composite use on the Internet. These distributed analysis services are accessible through an incrementally augmented software analysis catalog, where organizations and research groups can register and share their tools.
SOFAS is a RESTful architecture offering a simple yet effective way to provide software analyses. It is based on the principles of Representational State Transfer around resources on the web. The figure underneath gives an overview of the architecture, which is made up by three main constituents: Software Analysis Web Services, a Software Analysis Broker, and Software Analysis Ontologies. Software Analysis Web Services expose the functionality and data of software (evolution) analyses through a standard RESTful web service interface. The Software Analysis Broker acts as the services manager and the interface between the services and the users. It contains a catalog of all the registered analysis services. Ontologies define and represent the data consumed and produced by the different services. In the following, we briefly describe each of these three components:
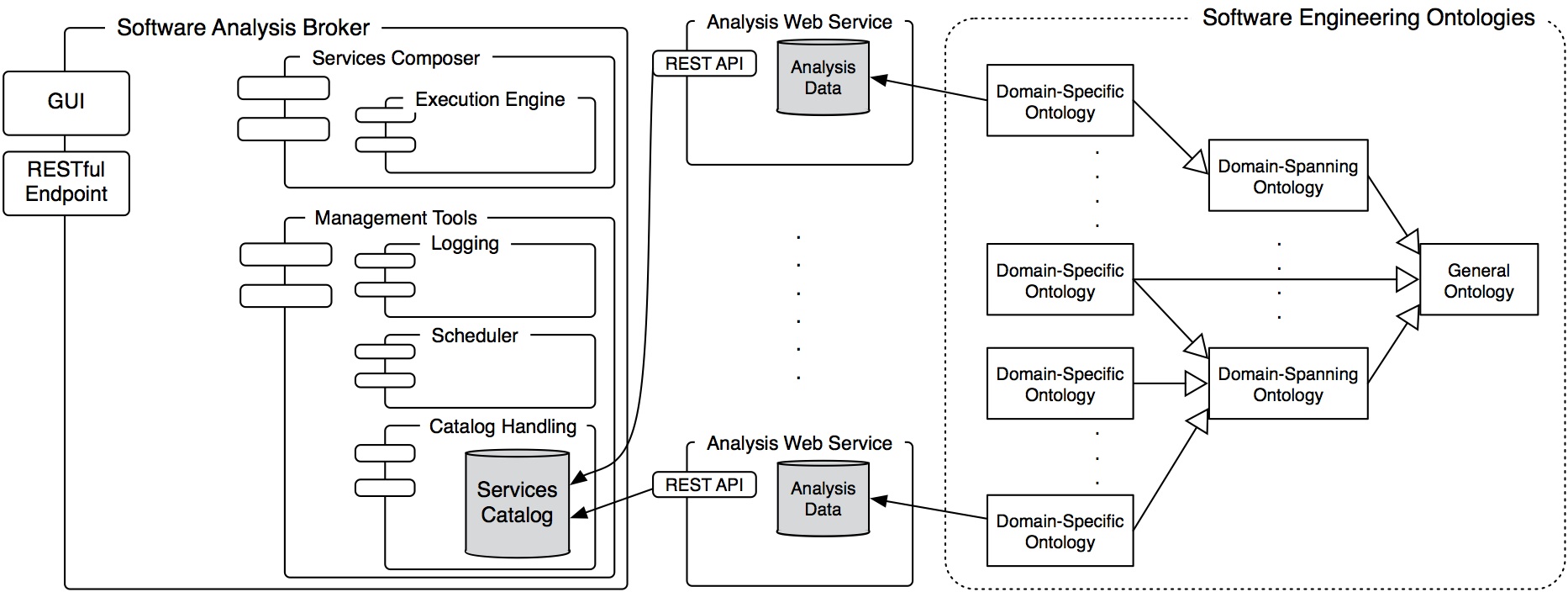
Software Analysis Web Services
SOFAS’ purpose is to provide software analyses and the data they produce in a simple, standardized way, freeing them from specific IDEs, platforms and languages. From a user’s perspective, software analyses are inherently linear and uniform in the way they work. Given some information about a software project (be it the code, its source code repository, some data already calculated by an analysis, etc.) and possible analysis calibration settings, they extract and/or calculate their specific data. Once that is completed, the results can be fetched in different, specific formats and, when needed, they can also be updated or deleted. Given these premises, RESTful services perfectly fit our needs. A RESTful web service provides a uniform interface to the clients, no matter what it actually does. It is a collection of resources all identified by URIs, which can be accessed and manipulated with HTTP methods (e.g., POST, GET, PUT or DELETE). Furthermore, every message exchanged is self-descriptive as it always contains the Internet media type of the content, which is enough to describe how to process it. In our case, the analyses services boil down to simply two resources: the service itself and the individual analyses.
These analyses can be classified into three main categories: data gatherers, basic software evolution analyses and composite software evolution analyses.
Service Analysis Broker
It acts as a layer between the services and the users, so that they do not have to interact directly with the raw services. It plays a vital role in facilitating the use of the services in an effective and meaningful way. The broker is made up of four main components:

Software Analysis Ontologies
We use ontologies to define and represent the data consumed and produced by the different services. To do so, we developed our own Software Evolution Ontology, called SEON. For a full description of it, please refer to its official web page
People interested in working with the SOFAS platform or even collaborating on it are invited to contact Prof. Harald Gall or Giacomo Ghezzi.